Mike's Notes
- The server has no public access.
- How to do this safely?
- See notes from
- Adobe Help
- CFDocs
- Ben Nadel (2020)
- Brian Harvey - Heartland Web Development (2015)
- Code examples below in yellow
Resources
- https://helpx.adobe.com/coldfusion/cfml-reference/coldfusion-tags/tags-d-e/cfexecute.html
- https://www.bennadel.com/blog/3812-running-cfexecute-from-a-given-working-directory-in-lucee-cfml-5-2-9-31.htm
- https://cfdocs.org/cfexecute
- https://www.hwdevelopment.com/blog/23-run-commands-via-ssh-to-a-remote-server-using-coldfusion-putty-and-plink
References
- Reference
Repository
- Home > Ajabbi Research > Library >
- Home > Handbook >
Last Updated
11/05/2025
CFExecute
Executes a ColdFusion developer-specified process on a server computer.
CFExecute
By: CFDocs:
name (string)
Absolute path of the application to execute.
On Windows, you must specify an extension; for example, C:\myapp.exe.
arguments (any)
Command-line variables passed to application. If specified as string, it is processed as follows:
- Windows: passed to process control subsystem for parsing.
- UNIX: tokenized into an array of arguments. The default token separator is a space; you can delimit arguments that have embedded spaces with double quotation marks.
- Windows: elements are concatenated into a string of tokens, separated by spaces. Passed to process control subsystem for parsing.
- UNIX: elements are copied into an array of exec() arguments
outputfile (string)
File to which to direct program output. If no outputfile or variable attribute is specified, output is displayed on the page from which it was called.
If not an absolute path (starting with a drive letter and a colon, or a forward or backward slash), it is relative to the CFML temporary directory, which is returned
by the GetTempDirectory function.
variable (string)
Variable in which to put program output. If no outputfile or variable attribute is specified, output is displayed on page from which it was called.
timeout (numeric)
Default: 0
Length of time, in seconds, that CFML waits for output from the spawned program.
errorVariable (string)
The name of a variable in which to save the error stream output.
errorFile (string)
The pathname of a file in which to save the error stream output. If not an absolute path (starting a with a drive letter and a colon, or a forward or backward slash), it is relative to the ColdFusion temporary directory, which is returned by the GetTempDirectory function.
terminateOnTimeout (boolean
Default: false
Lucee 4.5+ Terminate the process after the specified timeout is reached. Ignored if timeout is not set or is 0.
directory (string)
Lucee 5.3.8+ The working directory in which to execute the command
Running CFExecute From A Given Working Directory In Lucee CFML 5.2.9.31
When you invoke the CFExecute tag in ColdFusion, there is no option to execute the given command from a particular working directory. That's why I recently looked at using the ProcessBuilder class to execute commands in ColdFusion. That said, the default community response to anyone who runs into a limitation with the CFExecute tag is generally, "Put your logic in a bash-script and then execute the bash-script.". I don't really know anything about bash scripting (the syntax looks utterly cryptic); so, I thought, it might be fun to try and create a bash script that will proxy arbitrary commands in order to execute them in a given working directory in Lucee CFML 5.2.9.31.
The goal here is to create a bash script that will take N-arguments in which the 1st argument is the working directory from which to evaluate the rest (2...N) of the arguments. So, instead of running something like:
ls -al path/to/things
... we could run something like:
my-proxy path/to ls -al things
In this case, we'd be telling the my-proxy command to execute ls -al things from within the path/to working directory. To hard-code this example as a bash script, we could write something like this:
The hard-coded version illustrates what we're trying to do; but, we want this concept to by dynamic such that we could run any command from any directory. To this end, I've created the following bash script, execute_from_directory.sh, through much trial and error:
CAUTION: Again, I have no experience with bash script. As such, please take this exploration with a grain of salt - a point of inspiration, not a source of truth!
What this is saying, as best as I think I understand it, is take the first argument as the desired working directory. Then, use the shift command to shift all the other arguments over one (essentially shifting the first item off of the arguments array). Then, change working directory and execute the rest of the arguments from within the new working directory.
Because we are using the special arguments array notation, "$@", instead of hard-coding anything, we should be able to pass-in an arbitrary set of arguments. I think. Again, I have next to no experience here.
Once I created this bash-script, I had to change the permissions to allow for execution:
chmod +x execute_from_directory.sh
To test this from the command-line, outside of ColdFusion, I tried to list out the files in my images directory - path/to/my-cool-images - using a combination of working directories and relative paths:
total 17740
drwxr-xr-x 11 root root 352 Apr 11 11:28 .
drwxr-xr-x 4 root root 128 Apr 15 10:07 ..
-rw-r--r-- 1 root root 1628611 Dec 1 20:04 broad-city-yas-queen.gif
-rw-r--r-- 1 root root 188287 Mar 4 14:09 cfml-state-of-the-union.jpg
-rw------- 1 root root 3469447 Jan 28 16:59 dramatic-goose.gif
-rw------- 1 root root 2991674 Dec 14 15:39 engineering-mistakes.gif
-rw-r--r-- 1 root root 531285 Dec 1 21:10 monolith-to-microservices.jpg
-rw-r--r-- 1 root root 243006 Dec 24 12:34 phoenix-project.jpg
-rw-r--r-- 1 root root 1065244 Jan 22 14:41 rob-lowe-literally.gif
-rw-r--r-- 1 root root 7482444 Mar 25 10:15 thanos-inifinity-stones.gif
-rw-r--r-- 1 root root 239090 Dec 29 13:08 unicorn-project.jpg
As you can see, I've created an executeFromDirectory() User-Defined Function (UDF) which takes, as its first argument, the working directory from which we are going to execute the rest of the commands. Then, instead of executing the zip command directly, we are proxying it through our bash script.
And, when we run the above ColdFusion code, we get the following output:
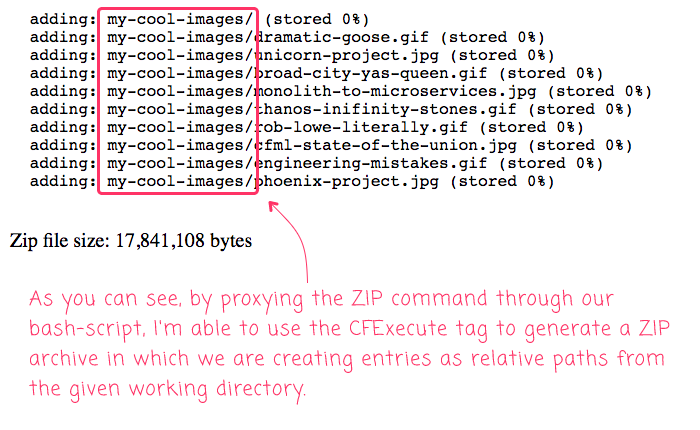
Very cool! It worked! As you can see from the zip debug
output, the entries in the archive are based on the relative paths
from the working directory that we passed to our proxy.
Now that I know that the ProcessBuilder class exists, I'll probably just go with that approach in the future. That said, it was exciting (and, honestly, very frustrating) for me to write my first real bash-script to allow the CFExecute tag to execute commands from a given working directory in Lucee CFML. Bash scripting seems.... crazy; but, it also seems something worth learning a bit more about.
You Might Also Enjoy Some of My Other Posts
- Using The Directory Attribute To Invoke CFExecute From A Working Directory In Lucee CFML 5.3.8.189
- Using Both STORE And DEFLATE Compression Methods With The zip CLI In Lucee CFML 5.3.6.61
- Using NPM Run-Scripts To Execute Shell Commands In Lucee CFML 5.3.6.61
- Executing Command-Line Processes From A Working Directory Using ProcessBuilder In Lucee CFML 5.2.9.31
- Zipping Image Archives With DEFLATE And STORE Compression Methods In Lucee CFML 5.2.9.31
- Error Variable Randomly Exists After Running CFExecute In Lucee CFML 5.3.3.62
Run commands via SSH to a remote server using ColdFusion, Putty and Plink
In order to create a real time dynamic IP whitelist solution for a
client I needed to be able to SSH into a pfSense fiewall using
ColdFusion and kick off a few .sh files to update the firewall's ip
whitelist. ColdFusion doesn't have the ability to SSH directly, but by
using <cfexecute>, Putty and Plink you can get the job done.
Here is how to do it:
1. Download Putty and Plink.
Putty is an SSH client
for windows, and Plink is a command line interface to Putty.
2. Launch Putty and create a "stored session" to the target server. I named my stored session "firewall". Now log into the remote server using the saved session so that an authentication key is generated and stored in Putty. Once you have generated an authentication key and are logged in you can exit your session and close Putty.

3. Now you can run <cfexecute> to SSH into the remote server and run .sh files.
<cfexecute name="C:\WINDOWS\system32\cmd.exe"
arguments="/c C:\plink.exe -v root@firewall -pw MyPassword /cf/conf/putconfig.sh" timeout="5">
</cfexecute>
There was one "gotcha" I discovered with running the command using ColdFusion. I was able to run the plink command all day long from the cmd prompt:
C:\plink.exe -v root@firewall -pw MyPassword /cf/conf/putconfig.sh.
But when I tried to run it as an argument in <cfexecute> it would fail. I was stumped until I came across this blog post by Ben Forta.
Ben points out that in Windows, you need to insert "/c" as the first argument in the string in order to tell Windows to to spin up a command interpreter to run and terminate upon completion.
This Works: arguments="/c C:\plink.exe -v root@firewall -pw MyPassword /cf/conf/putconfig.sh" timeout="5"
This Doesn't Work: arguments="C:\plink.exe -v root@firewall -pw MyPassword /cf/conf/putconfig.sh" timeout="5"
That little extra had me spinning my wheels for the better part of a day until I ran across Ben's post.